How I Would Design… Yelp or Nearby Friends
A System Design Demonstration
Audience
This article is the next in my series of how I would design popular applications. It is recommended (although not entirely necessary) to read the previous posts I’ve helpfully compiled in a list here. We will expect a basic familiarity with architecture principles and AWS, but hopefully this post is approachable for most engineers.
Argument
Initially, let’s look at our problem statement.
The System to Design
In all honesty I’ve never used Yelp or Nearby friends, I tend to use Google Maps! However, the idea is the same. You are represented by a point on a map, and you can search in your immediate vicinity for things like pubs, restaurants, pubs, theatres, pubs, cinemas, pubs, train stations, or even pubs! If you’ve not used one of these services before an example using Google Maps is here.
Our system requires the following:
- We need to be able to search for locations by name and location.
- We need to be able to comment/ rate and upload photos of locations.
Our usual non-functional requirements stand. It must be reliable, scalable and available.
The Approach
We have a standard approach to system design which is explained more thoroughly in the article here. However the steps are summarised below:
- Requirements clarification: Making sure we have all the information before starting. This may include how many requests or users we are expecting.
- Back of the envelope estimation: Doing some quick calculations to gauge the necessary system performance. For example, how much storage or bandwidth do we need?
- System interface design: What will our system look like from the outside, how will people interact with it? Generally this is the API contract.
- Data model design: What our data will look like when we store it. At this point we could be thinking about relational vs non-relational models.
- Logical design: Fitting it together in a rough system! At this point I’m thinking at a level of ‘how would I explain my idea to someone who knows nothing about tech?’
- Physical design: Now we start worrying about servers, programming languages and the implementation details. We can superimpose these on top of the logical design.
- Identify and resolve bottlenecks: At this stage we will have a working system! We now refine the design.
With that said, let’s get stuck in!
Requirements Clarification
The first thing I would be wondering would be how many users we would be expecting and how frequently they will be using the system. I would also want a rough estimate of the number of locations, the memory requirements of a location, the average number of locations returned per search and the average image size.
Let’s say we have 2 million locations. We have 1 million users, each of which are reading twice a day with 10 results, and writing once a week. A location takes up around 1MB of storage, whereas an image takes about 100KB (these estimates aren’t that realistic).
Back of the envelope estimation
We can turn the above requirements into a back of the envelope estimation. 1,000,000 * 2 * 10 = 20,000,000 reads a day = 240 reads a second. Equally, 1,000,000 = 1.5 writes a second. Initially we see we have a read heavy system. We’re reading 240MB/s (not including image requests) and writing around 150KB/s (assuming reviews and comments are around the same size as an image).
In terms of storage, we’re going to need around 2,000,000 * 1MB = 2TB of storage, not including adding more locations!
System interface design
Having decided we’ve got a fairly big system on our hands, let’s look at how we would like to interact with it. Initially we would like to be able to search by name or location. We can do this by using a GET request to /search?query=<query text> or /search?longitude=<longitude>&latitude=<latitude> endpoints, which return a list of locations. We could add more parameters (radius, maximum results etc.), but we will standardise this for now.
A location object may look similar to the below:
Note, we’ve assumed that the rating system is essentially a liking system, where the count is the number of likes.
From this endpoint we can then return a 200 for a successful response, with the usual 4XX, 5XX errors if anything goes wrong.
Commenting, rating and photos follow a similar pattern. We can use a POST request to /location/{id}/comments, /location/{id}/ratings or /location/{id}/images. The body of the post to comments can use the comment object included in the location.json. A rating wouldn’t need much in the body, it would be enough just to say someone has liked it.
The image would be slightly more complex. We might think of using a form and multipart-form-data. A more thorough coverage of this is in the article here.
Each of these endpoints would return a 201 for created, then the regular 4XX and 5XX error codes.
Note, we’re not bothering with tracking users in this example, but in the real world we would need some sort of user management. We’re also assuming users can’t submit locations, only read them.
Data model design
The next thing we need to do is design our data model. We have a very solid location object, however we need to understand how we might map that to persistent storage.
There are two options, SQL and NoSQL. SQL offers us consistency of data, which is good in some respects. However, in this case consistency doesn’t bother us too much. If a user doesn’t see a location or review for a few moments, that’s not too big a worry. We can also leverage the scalability of NoSQL to support the demand on our service. Let’s go for NoSQL.
The other thing we need to understand is how our data model will affect our search capabilities. Let’s pretend we’re always searching for locations within a 10 mile radius of our current location.
One naive approach would be to have a massive SQL table with longitude and latitude columns, where we search for all locations with both fields within a 10 mile radius. However, we can immediately see this would become ineffective the more locations we get.
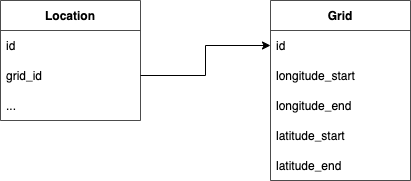
A better approach would be to divide our map into grids.

In this design we have split London up into small squares, each of which contains a number of locations. To calculate the locations in a radius we can search for the current and adjoining grids.
We originally had two million locations. Let’s say the earth is one million kilometres squared (highly unlikely, but roll with it for the sake of example). We break the world map down into squares of 10km squared. This makes 1,000,000 / 10 = 100,000 squares. Suddenly we’ve moved from searching two million rows, to searching 100,000!
There may be further issues with this approach. There’s a lot of things to do in London, but less so in the middle of the Pacific Ocean! Some of our grids may be empty, and some of them may be far too full.
Enter, the QuadTree. At its core this is a tree structure where each node has four children. For those of you less familiar with trees, I’d recommend reading my article here, and my article on tries here. The tries article is especially relevant as it demonstrates the process of setting a threshold, after which we break down a node into other nodes.
Imagine we have a tree design as below:
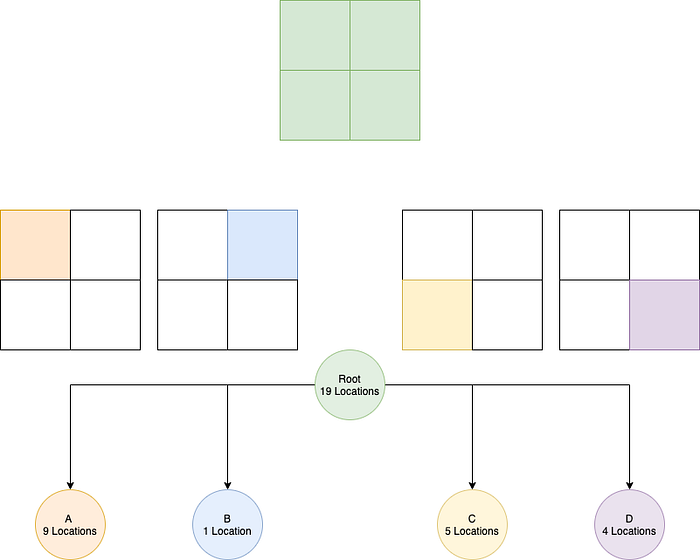
Initially, our root node represents our entire map (hence all the squares are green). We can split this area down further into four quadrants, represented by A, B, C and D, each containing their relevant location information. The trigger we have for doing this splitting is a threshold, which has been set at 10. What this means is every time a node has 10 locations we split it down further.
We can add another location to A to demonstrate.
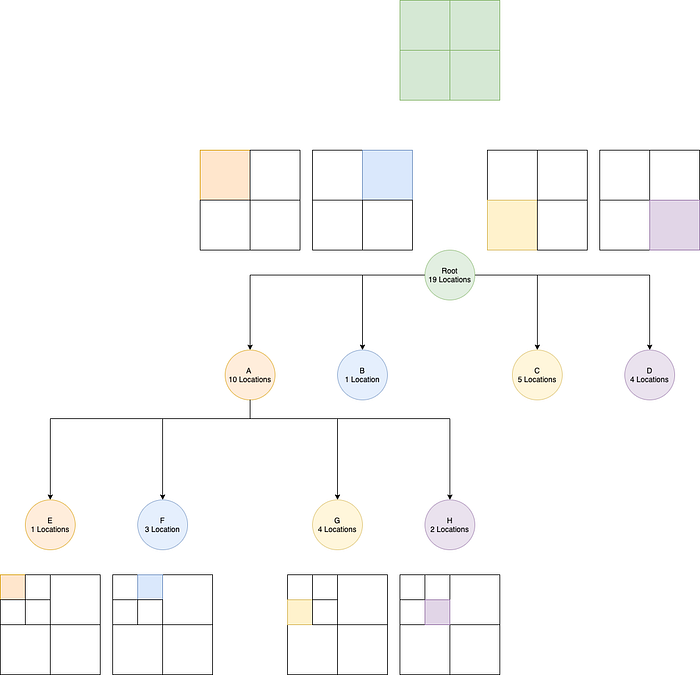
To search we then recurse down the tree! This is our index of areas to location Ids.
Logical design
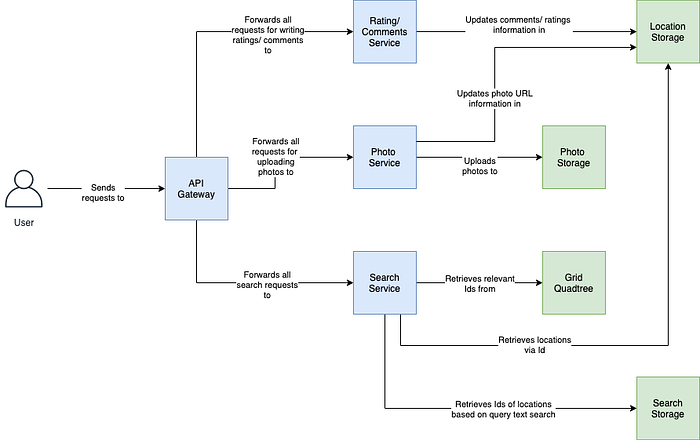
A user sends their requests to an API Gateway, which forwards requests for writing ratings and comments to one service, requests for uploading photos to another service, and search requests to another.
The ratings/ comments service is responsible for updating the persisted locations with ratings/ comments information. The photo service receives photo upload requests and is responsible for saving them to some form of storage. Note, we’re ignoring encoding for this example, as otherwise the system will get too complex to be helpful.
Finally, the search service interacts with the grid quadtree for retrieving location Ids dependent on longitude and latitude, then using these to query the location storage. It can also looks up any query text using the inverted index.
Although this seems fairly straightforward, when we move onto the later section we’ll see there’s a lot of optimisation to be done!
Physical design
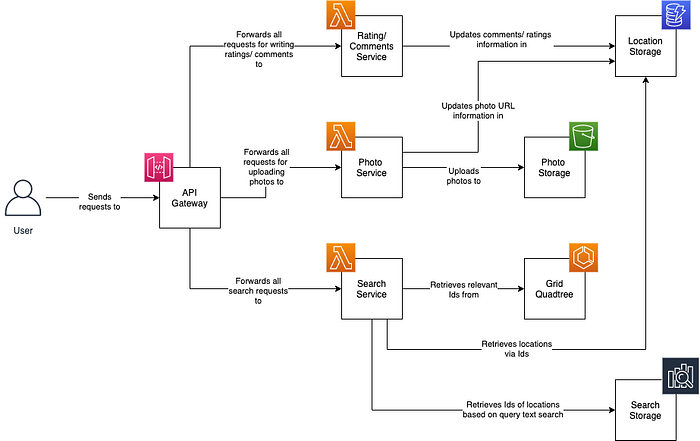
Here is a proposed initial physical design. All requests are sent to an AWS API Gateway, and there are three Lambdas subscribed to it, each representing one of the consuming services. Our location storage is done through DynamoDb, our image storage is done in S3.
We’re hosting our grid quadtree on a cluster of ECS instances. Notice, this is different to distributing the quadtree. We will have several copies of the tree, but the whole tree will reside on each node. Our inverted index will be done using AWS OpenSearch.
An interesting point to note is some people don’t separate out their NoSQL storage and their index. This is fine, you can use ElasticSearch as your primary data storage. However, I probably wouldn’t recommend it, unless your use case definitely doesn’t depend on any of the properties mentioned in that article.
Identify and resolve bottlenecks
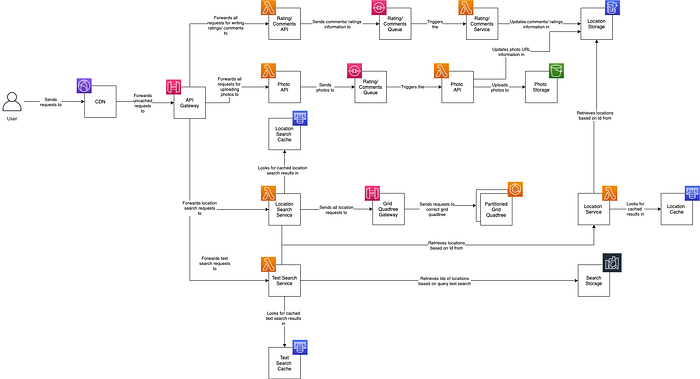
The first step we can make to optimise our design is the introduction of a CDN. Let’s use this as an opportunity to dive into how they work.
CDNs
When we host our site, we are normally hosting it from a set region of the world. Let’s say it’s hosted in Europe. If a user wants to visit it from San Francisco then the information must travel all the way between continents! This can be quite slow.
It would be useful for us to be able to store copies of parts of the website all over the world. For example, if we know a page won’t change frequently, we can store a copy in L.A., improving the San Francisco load times.
This is the role of CDNs. These geographically distributed servers help cache content including HTML, Javascript, stylesheets, video, and images. It can also improve security, reduce costs, and increase availability. Pretty nifty, eh?
Improving security is done in a couple of ways. Initially, as we will discuss, users can connect directly to a CDN. This means that we can use the CDN’s certificate and connection for TLS/SSL (for a recap on TLS/SSL you can see my article here).
CDNs will prioritise making their connections as secure as possible, and will handle certificate rotation, which takes a load off our backs.
They also provide protection against DDoS attacks. They can detect unusual traffic patterns, respond by dropping suspicious packets, route remaining valid traffic, and adapt for the future by remembering previously offensive parties.
So how do we set up a CDN for our service?
In a cloud-driven world we might use something like AWS Cloudfront, which we set up in front of our web-facing service. Requests are no longer sent to our service, but instead all proxied through the CDN. In our responses we may express caching headers to tell our CDN more about how long it should keep hold of this response, or alternatively we may update the CDN manually with new files.
Allowing the CDN to request content before caching it is known as the ‘pull’ method, whereas putting our own files up is known as ‘push’.
The other thing we can do to improve our performance is partitioning. As our system grows we need to be able to scale, and at some juncture we will no longer be able to store our all of our information on single servers.
There are two main places we can look at partitioning our data. At the quadtree level and at the location level.
Sharding the quadtree we can do by region. To clarify, imagine we want to split our tree in half. All we need to do is split the tree, put one half on one server, and the other on another. We then introduce a gateway component in front of the servers, forwarding requests to the required servers.
There is a potential to introduce an index between the quadtree server number and the places stored on it, however it seems a bit unnecessary.
We can shard the locations by their Id. When one of our search services returns a location Id, a component in front of our fleet of servers will be responsible for directing the request to the appropriate place.
We would also introduce replicas of our data, and allow failovers in case of emergency.
Another optimisation we could do would be to separate out our search services, one in front of the quadtree, one in front of OpenSearch, and then a third one serving up requests for locations based on grid Id. We can also add a cache to our search services.
Finally, we can add resiliency by putting queues in between the write services and changing the response codes to 201 (accepted). This means if downstream systems are unavailable we don’t lose information.
Our finished design would look similar to the below.
Conclusion
In conclusion we have covered the requirements, design and implementation of a system similar to Yelp/ Nearby Friends.
